
Mask3D
trained on manual labels. Segment3D
trained on automatic labels.
trained on manual labels. Segment3D
trained on automatic labels.
Current 3D scene segmentation methods are heavily dependent on manually annotated 3D training datasets. Such manual annotations are labor-intensive, and often lack fine-grained details. Importantly, models trained on this data typically struggle to recognize object classes beyond the annotated classes, i.e., they do not generalize well to unseen domains and require additional domain-specific annotations. In contrast, 2D foundation models demonstrate strong generalization and impressive zero-shot abilities, inspiring us to incorporate these characteristics from 2D models into 3D models. Therefore, we explore the use of 2D foundation models to automatically generate training labels for 3D segmentation. We propose Segment3D, a method for class-agnostic 3D scene segmentation that produces high-quality 3D segmentation masks, improves over existing 3D segmentation models (especially on fine-grained masks), and enables easily adding new training data to further boost the segmentation performance - all without the need for manual labels.
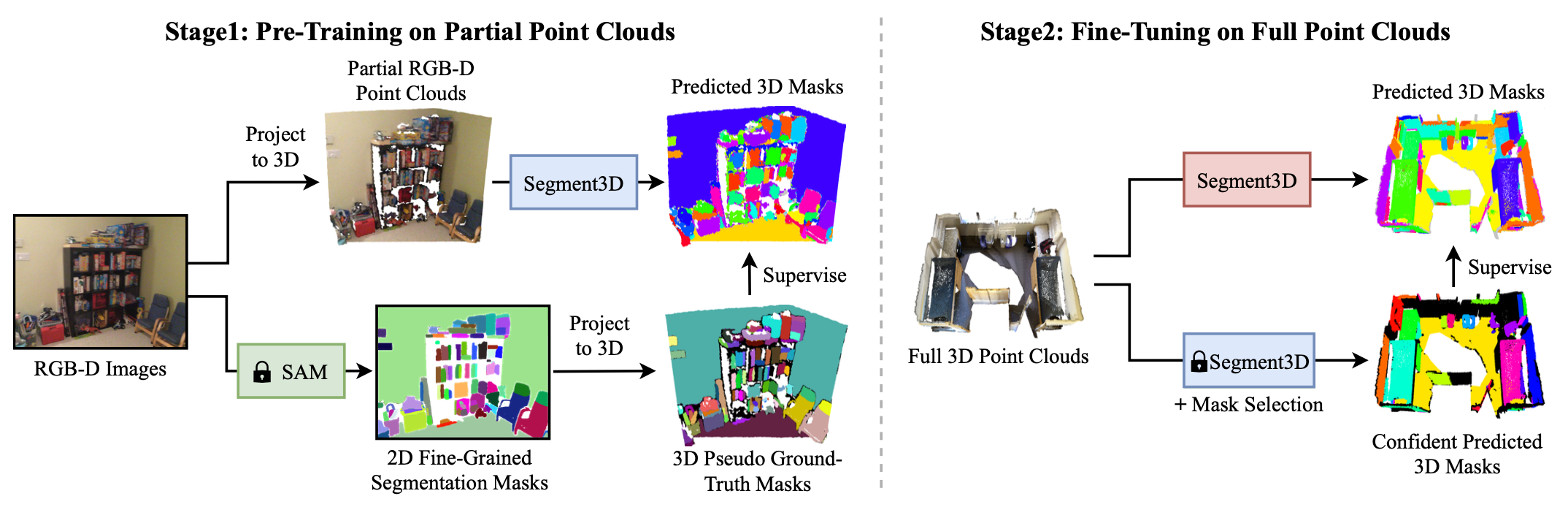
Training Segment3D involves two stages: The first stage (left) relies on largely available RGB-D image sequences and SAM, a pre-trained foundation model for 2D image segmentation. Segment3D is pre-trained on partial RGB-D point clouds and supervised with pseudo ground-truth masks from SAM projected to 3D. Due to the domain gap between partial and full point clouds, in the second stage (right), Segment3D is fine-tuned with confident masks predicted by the pre-trained Segment3D.
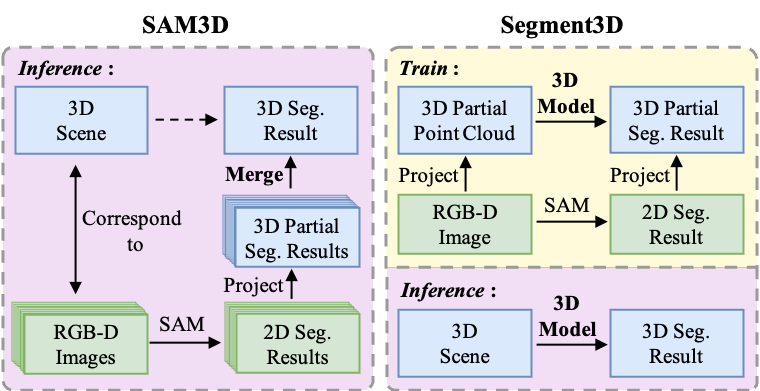
SAM3D merges the segmentation masks of RGB-D images generated by SAM to obtain the segmentation result for the entire scene. The merging process introduces noise due to heuristic merging rules and conflict segmentation results across overlapping frames. Moreover, it is slow because of extensive image inference and the cumbersome merging procedure. Instead, Segment3D utilizes a native 3D model to directly segment the entire scene, which is clean and efficient.

Qualitative Results on ScanNet++ Val Set. From top to bottom, we show the colored input 3D scenes, the segmentation masks predicted by SAM3D, Mask3D, our Segment3D and the ground truth 3D mask annotations.

Segment3D also exhibits superior generalization performance compared to Mask3D on unseen outdoor scenes.

Given a text prompt (bottom), OpenMask3D finds the corresponding masks in a given 3D scene (top). We adapt OpenMask3D and use fine-grained masks from our Segment3D method. We show the 3D scene reconstruction and an RGB image for better visualization (top left corner).

An Example of Open-Set 3D Object Retrieval in a Scene: Segment3D can accurately generate fine-grained masks in a class-agnostic manner, allowing us to retrieve small-scale objects of interest.
@article{Huang2023Segment3D,
author = {Huang, Rui and Peng, Songyou and Takmaz, Ayca and Tombari, Federico and Pollefeys, Marc and Song, Shiji and Huang, Gao and Engelmann, Francis},
title = {Segment3D: Learning Fine-Grained Class-Agnostic 3D Segmentation without Manual Labels},
journal = {European Conference on Computer Vision (ECCV)},
year = {2024}
}